Infrastructure as Code (IaC) is a force multiplier: it speeds up delivery, makes environments reproducible, and enables teams to scale. But it also scales mistakes. One weak default, one rushed exception, one missing check — and you can ship a security incident at CI/CD velocity.
Executive summary
- IaC accelerates deployments, but it also accelerates misconfiguration risk, security breaches, and compliance failures.
- Guardrails are automated policy checks that prevent unsafe changes, detect drift, and correct violations fast.
- Done well, guardrails improve security and auditability without slowing engineers down — they replace tribal knowledge with testable rules.
Note: This is a generic pattern. No client specifics. Treat the numbers below as illustrative targets, not promises.
The problem: a compliance nightmare (hypothetical)
Picture “Granite Bank” (hypothetical). Multiple teams ship cloud storage changes through IaC. One week, an innocuous module update makes a set of storage buckets publicly accessible. The exposure is not caught until days later.
- Hundreds of storage buckets become public due to a misconfiguration.
- Manual reviews miss it because the change is spread across repos and environments.
- Regulators ask for evidence: who approved what, which controls failed, and why it wasn’t detected sooner.
Root causes are usually boring and repeatable:
- Missing automated policy enforcement in CI/CD.
- Fragmented tooling and inconsistent modules.
- Developer pressure: speed wins over verification when checks are manual.
The solution: guardrails as a framework
Effective IaC guardrails combine three layers:
- Preventative: block unsafe infrastructure changes before deployment.
- Detective: continuously scan live environments for drift and violations.
- Corrective: automate remediation workflows to fix issues rapidly and consistently.
The simplest mental model is: policy as code + pipeline gates + runtime drift checks + exception handling + audit evidence.
Practical implementation approach
- Map risk and requirements: translate key risk statements into testable rules (encryption, public exposure, identity boundaries, logging).
- Select enforcement points: pre-commit checks, pull-request gates, plan/apply gates, and continuous runtime evaluation.
- Define policies as code: start with “never events” (public access, weak encryption, unmanaged admin access) before fine-grained rules.
- Integrate into CI/CD: fail fast with clear messages, plus a documented exception path.
- Close the loop: emit evidence automatically (policy decision, actor, commit, environment, remediation ticket, timestamp).
Business benefits
These are illustrative targets you can use to set expectations during a pilot (validate with your own baselines):
- Target: reduce high-severity cloud misconfigurations by 40% within 90 days of rolling out preventative policy gates.
- Target: achieve 95% control coverage (for defined “never events”) via automated policy evaluation and drift checks.
- Target: reduce rollback/rework cycles by 30% through consistent pre-deployment verification.
- Target: cut time-to-detect for policy violations from days to minutes using continuous scanning and alerting.
Use cases that justify the investment
- Rapid response to newly disclosed vulnerabilities by blocking known-bad images or configurations at the pipeline gate.
- Always-compliant infrastructure stacks using drift detection and automated correction.
- Multi-cloud guardrails: consistent policies evaluated across Terraform, CloudFormation, and platform-native controls.
Technology stack overview
- IaC tools: Terraform, CloudFormation
- Policy engines: Terraform Sentinel, Open Policy Agent (OPA)
- Cloud compliance: AWS Config, Azure Policy
- CI/CD platforms: GitHub Actions, Jenkins
- Remediation: AWS Lambda, Azure Functions
- Source control: GitHub, GitLab
- AI assistance: GitHub Copilot (for policy generation and refactoring, with review)
Policy examples (shown as images)
Note: These examples are simplified. Adapt them to your standards, threat model, and cloud/provider specifics. Keep the “exception path” explicit and auditable.
Example 1: Block public storage exposure (Sentinel)

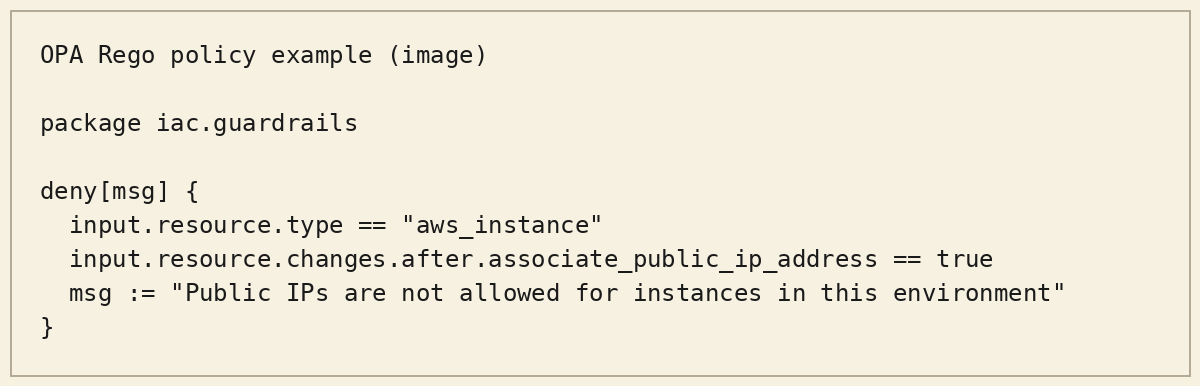
Example 2: Deny public IPs by default (OPA / Rego)
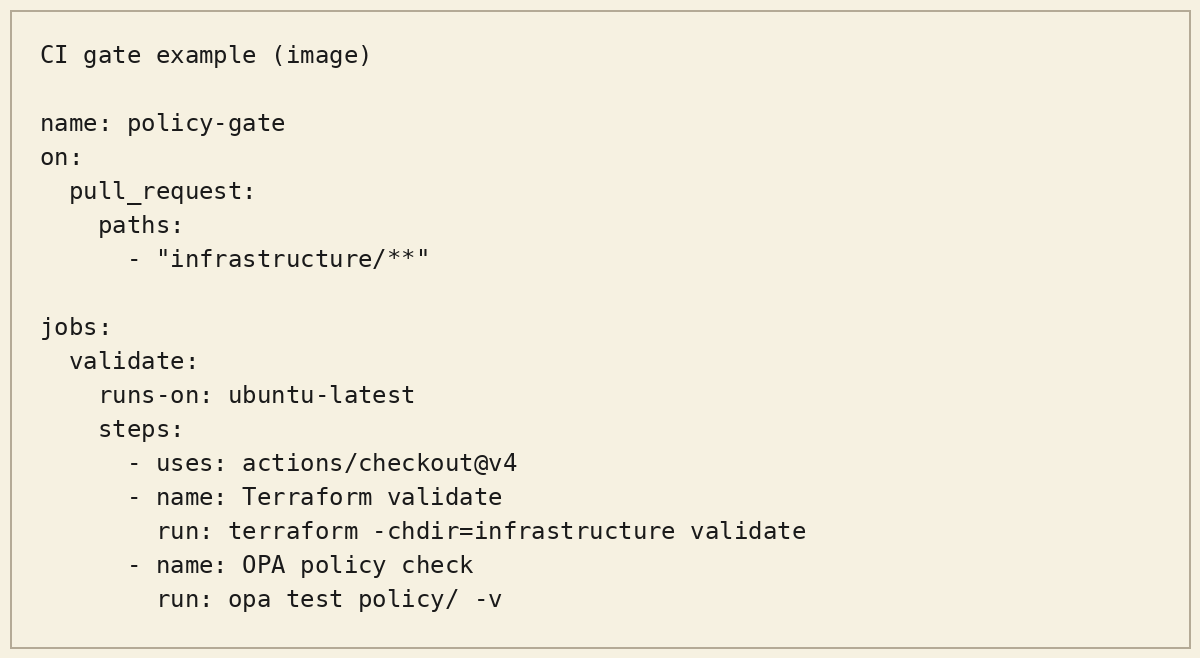
Example 3: CI gate that fails on policy violations (GitHub Actions)
Next steps
- Run a short risk and compliance assessment to identify the top “never events”.
- Pilot guardrails on one critical repo or one platform team for 4–6 weeks.
- Publish a lightweight exception process (who approves, what evidence is required, expiry dates).
- Scale guardrails incrementally across the estate, backed by metrics and audit-ready evidence.
Collaboration welcome: if you want to strengthen the patterns, share corrections, counterexamples, or an artifact idea — grcguy@rtapulse.com • Discussions • Issues • LinkedIn (opens on LinkedIn) • How to collaborate.